
Excel on MacOS has its own quirk when dealing with CSV file. If you have a CSV file that is encoded with UTF-8 and contains entries in multibyte characters from East Asian languages such as Chinese, Japanese, Koreans, opening the file in Excel on MacOS may give you some surprise. Instead of showing the East Asian characters, Excel will display garbled characters.
Let us a run experiment to explain this case. We will use Node JS to create a CSV file, encode the file using UTF-8 and then try to open it using Excel on MacOS.
The Node JS code that we use to create the UTF-8 CSV file is as follows.
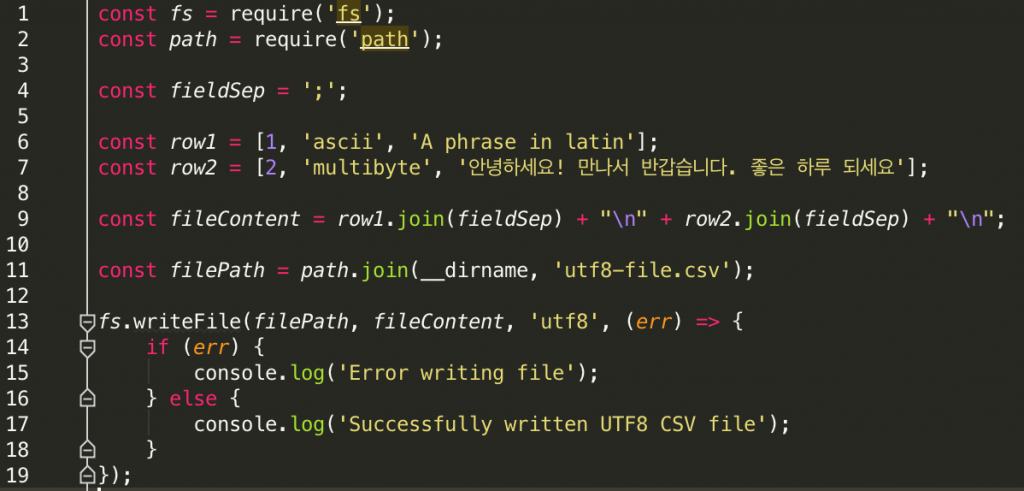
If you’re not familiar with Node JS, here is the explanation about what the code is doing line by line.
Line 1: The built-in Node JS fs module is used to handle the process of writing the UTF-8 CSV file
Line 2: We also use Node JS path module to build file path for storing the CSV file
Line 4: We use semicolon ‘;’ to separate fields in every row entry
Line 6-7: The content of the CSV file. There are two rows. The first row only contains single-byte latin characters. The second row contains mix of latin and multi-byte east asian characters that are represented by Korean phrases.
Line 9: We concatenate the row entries. Each row is appended with newline character “\n” so that the second row goes to the next line.
Line 11: We declare the output CSV file name. We put the file in the same directory with the JS file
Line 13-19: We write the row entries using UTF-8 encoding into the output CSV file.
Now let’s open the CSV file using a UTF-8 friendly text editor. This time, we’ll choose to open with Sublime Text.
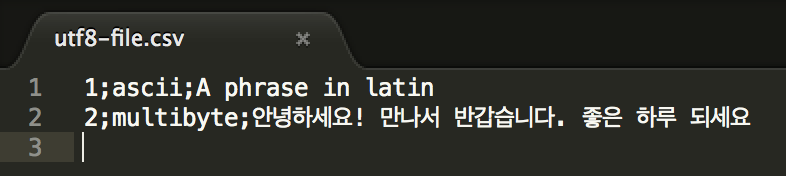
As seen in the snapshot, the Korean characters are displayed properly. Now, let’s open the same file with Microsoft Excel.
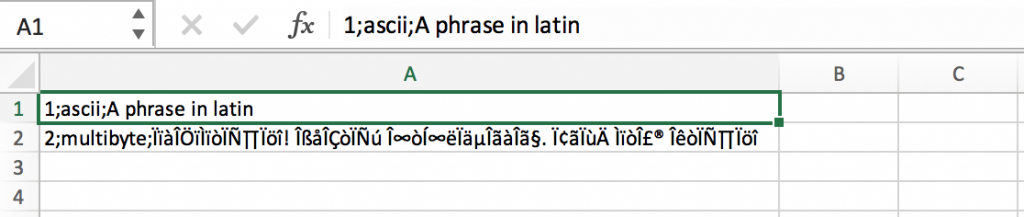
Suprisingly, when the CSV file is opened with Microsoft Excel, it exhibits two kinds of unexpected behavior:
- The semicolon has no effect to separate the fields. Instead of spreading the row fields into several columns, the row entry is shown in a single column.
- Garbled characters are displayed instead of the originally written Korean characters.
It turns out that Excel on MacOS will display multibyte CSV file properly if the following rules are applied when generating the file:
- Tab character “\t” is used to separate fields in a row entry
- Instead of UTF-8, the CSV file should be encoded with UTF16-LE (UTF16 Little Endian)
If we apply these rules to the Node JS code that generates the CSV file, the code shall be modified as follows:
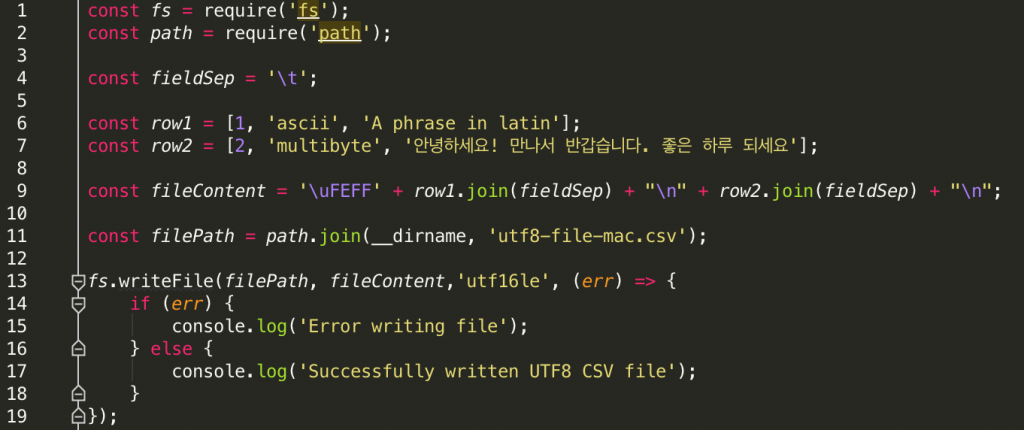
There are three main changes made in the modified code:
Line 4: The field separator is now changed to tab character from semicolon
Line 9: We add Byte Order Mark (BOM) 0xFEFF to explicitly hint that the string data is encoded in UTF16-LE
Line 13: We change the file encoding from UTF-8 to UTF16-LE when writing the file to disk
After applying the rule, let’s see how the content is displayed. First, we open the file using the text editor.

Again, the Korean characters are displayed properly. We also see that a field in a row is separated to the next field by a tab. How about opening the file in Excel? So, here it goes.

Unlike the previous setting with UTF-8 encoding, this time the content with the Korean characters is displayed properly.
To summarize, if you’re creating a CSV file with multibyte characters for example those of East Asian languages and you want to open it in Excel on MacOS, make sure that:
- The field is separated by a tab character
- The content is encoded in UTF16-LE
- The content is prefixed with UTF16-LE BOM
Appendix
We use Node JS to generate the multibyte CSV file in the example. It is important to note that Node JS will not add BOM when writing the file even though the encoding is specified in the option. This leads to interesting behavior when trying to write data that contains multibyte characters.
1. When writing string data that contains multibyte characters without BOM-prefix into a file, certain text editor would fail to display the data properly even though encoding is set to UTF16-LE.
...
const fileContent = row1.join(fieldSep) + "\n" + row2.join(fieldSep) + "\n”;
const filePath = path.join(__dirname, 'utf8-file-mac-alt1.csv’);
fs.writeFile(filePath, fileContent,'utf16le', (err) => {
...If we open the file created using this approach in Mac’s TextEdit and Sublime Text, we will see that TextEdit fails to display the content properly even though Sublime Text does not disappoint.
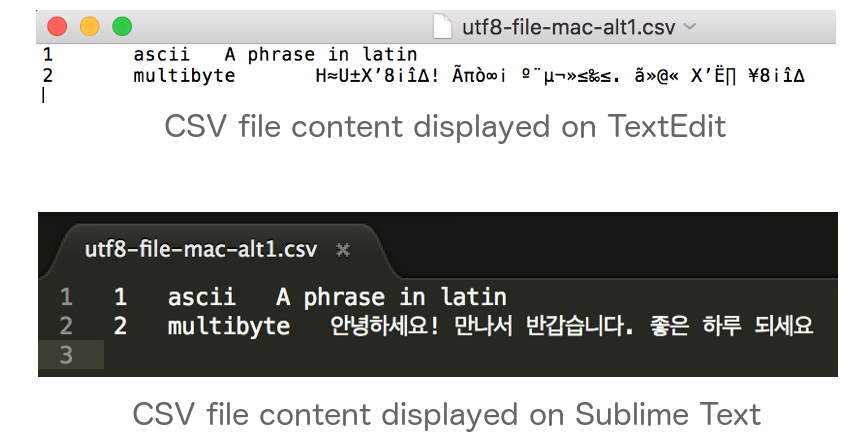
We then use a hex editor to view the content of the file as hex characters.
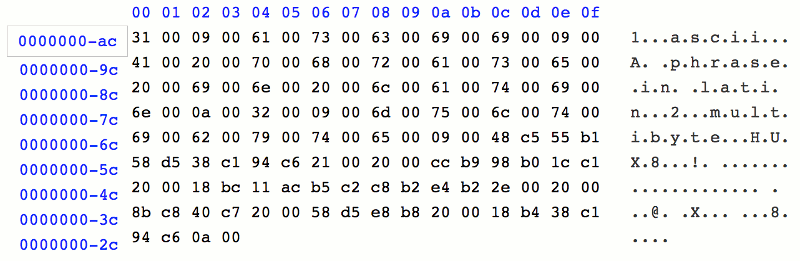
As seen in the picture above, there is no BOM character at the beginning of the file.
2. When writing string data that contain multibyte characters without BOM-prefix into file, text editors will properly display the content if it is converted into buffer and then converted again to UTF16-LE. However, it will not be displayed properly on Excel. Also, the tab character has no effect in separating the fields in a row.
...
const fileContent = row1.join(fieldSep) + "\n" + row2.join(fieldSep) + "\n";
const filePath = path.join(__dirname, 'utf8-file-mac-alt2.csv');
fs.writeFile(filePath, Buffer.from(fileContent).toString('utf16le'),'utf16le', (err) => {
...The file content when opened in text editors (TextEdit, Sublime Text) can be seen in the following image.
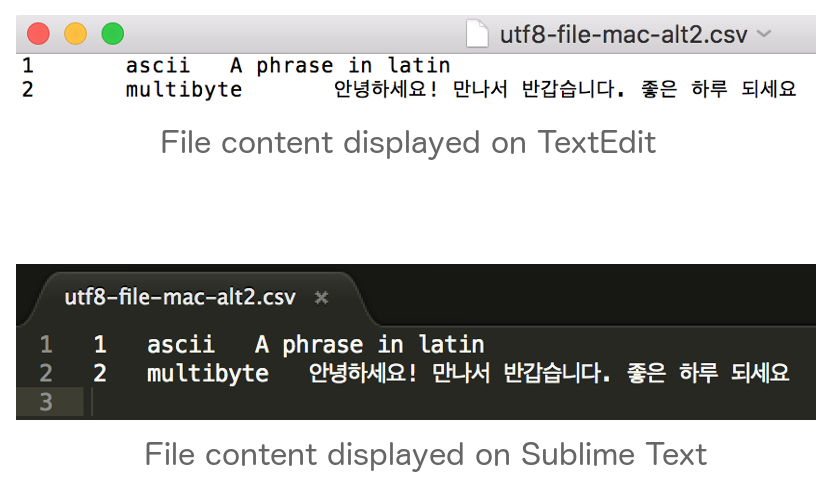
As shown in the image, content is properly displayed. However, this does not hold true when the file is opened in Excel.
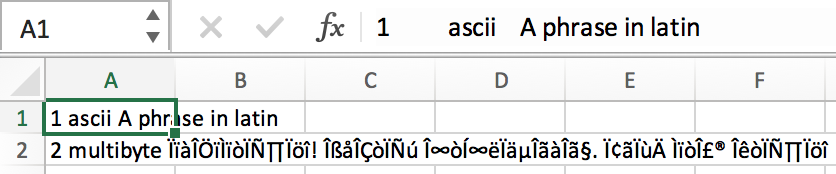
We then use the hex editor once again to display the file content as hex characters.
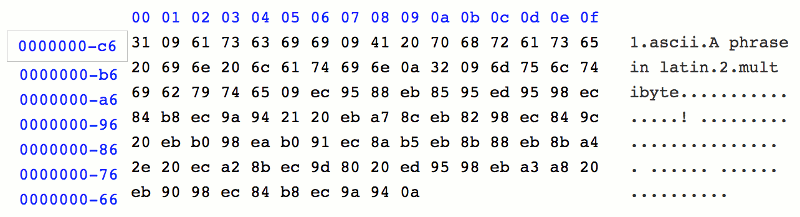
Despite the absence of BOM in the file, we can see that different with the previous hex view where each character is represented as two bytes, the current hex view is more compact in character representation. Nonetheless, the absence of BOM fails proper data display on Excel.
3. When BOM is added at the beginning of the content, text editors and Excel displays the content properly.
We verified the existence of BOM, by analyzing the file content again in the hex editor.
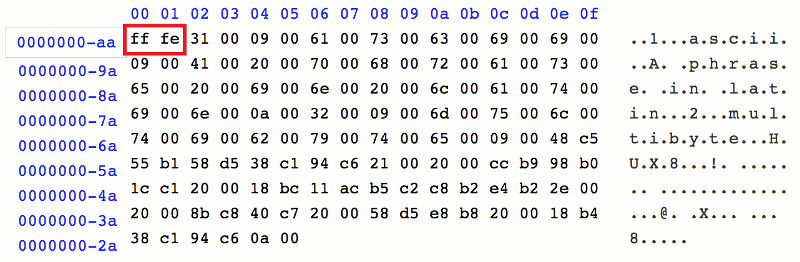
As seen in the picture, the BOM exists at the beginning of the file (red box), which results in the file content displayed properly when opened by various applications.
A rule of thumb would be to always prefix file containing multibyte East Asian characters encoded with UTF16-LE with BOM. When such file is programmatically created by using Node JS, the BOM character must be manually prepended since Node JS does not automatically add BOM to the data.
References
1. RFC 2781. UTF-16, an encoding of ISO 10646. Section 3.2 Byte Order Mark (BOM)
2. Node JS Issue #11767: Add option to automatically add BOM to write methods
Thanks a lot for this article, I very interested with this published
Thanks for your efforts.